划分数据的原则是:将无序的数据变得更加有序,组织杂乱无章的数据的一种方法就是使用信息论度量信息。在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。集合信息的度量方式称为香农熵(Entropy),这个名字来源于信息论之父 Claude Elwood Shannon
def chooseBestFeatureToSplit(dataSet):
numFeatures=len(dataSet[0])-1
baseEntropy=calcShannonEnt(dataSet)
bestInfoGain=0.0
bestFeature=-1
for i in range(numFeatures):
featList=[example[i] for example in dataSet]
uniqueVals=set(featList)
newEntropy=0.0
for value in uniqueVals:
subDataSet=splitDataSet(dataSet,i,value)
prob=len(subDataSet)/float(len(dataSet))
newEntropy += prob*calcShannonEnt(subDataSet)
infoGain=baseEntropy-newEntropy
if(infoGain>bestInfoGain):
bestInfoGain=infoGain
bestFeature=i
return bestFeature
def createTree(dataSet,labels):
classList=[example[-1] for example in dataSet]
#类别相同则停止分类
if classList.count(classList[0])==len(classList):
return classList[0]
#遍历完所有特征时返回出现次数最多的类别
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
#得到列表包含的所有属性值
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
def getNumLeafs(myTree):
numLeafs=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs+=getNumLeafs(secondDict[key])
else:
numLeafs+=1
return numLeafs
def getTreeDepth(myTree):
maxDepth=0
firstStr=myTree.keys()[0]
secondDict=myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth=1+getTreeDepth(secondDict[key])
else:thisDepth=1
if thisDepth>maxDepth:maxDepth=thisDepth
return maxDepth
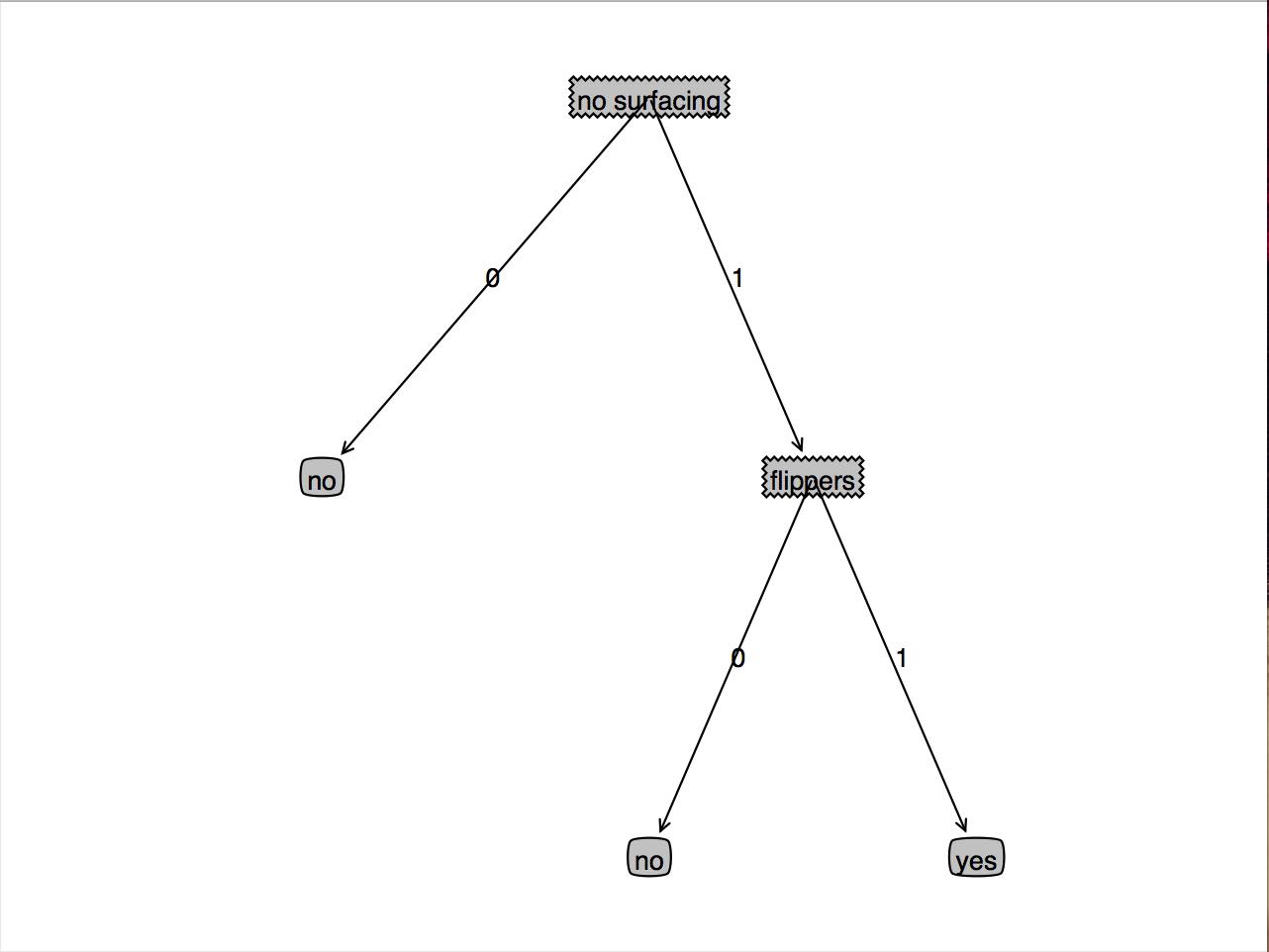
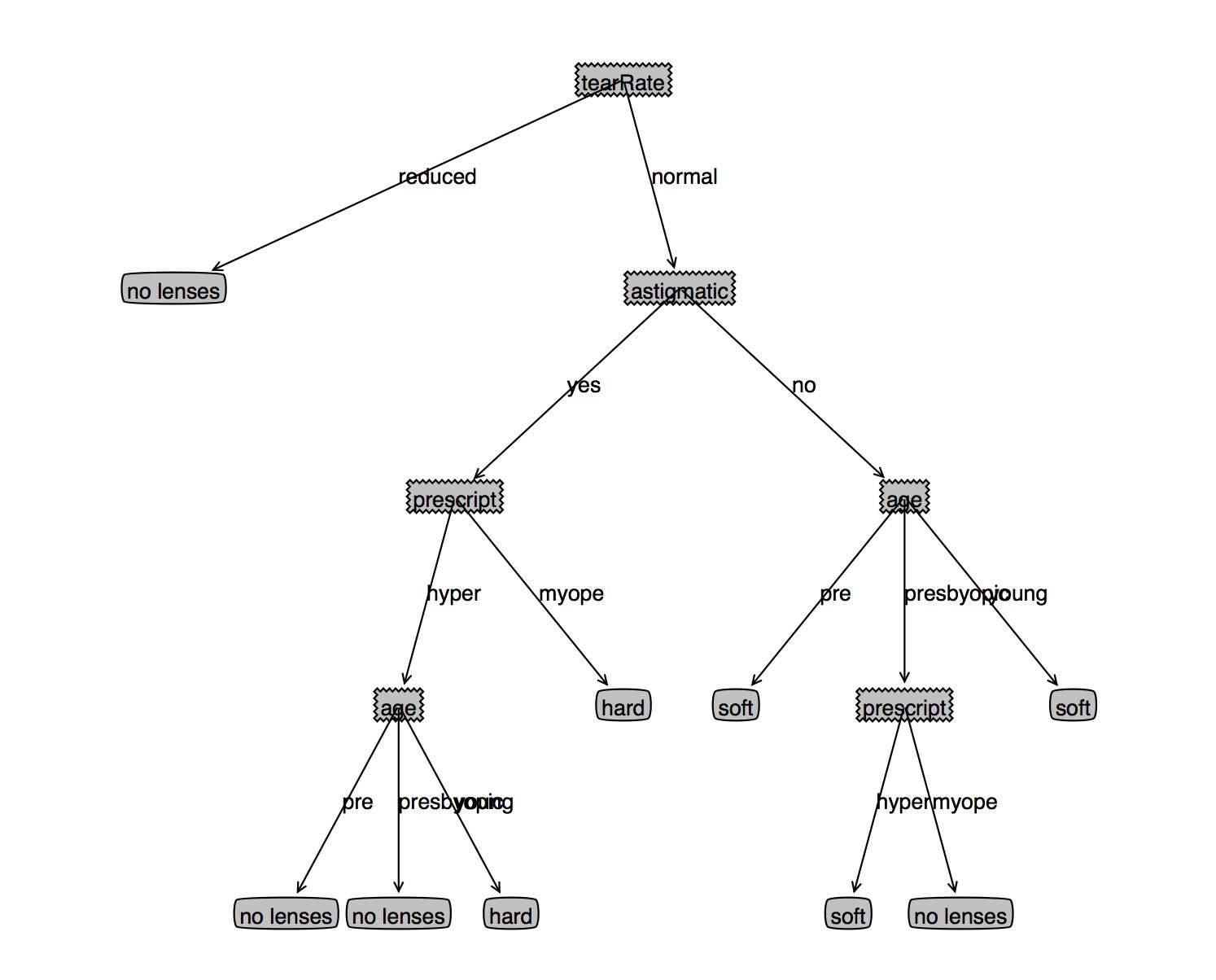
fr=open('lenses.txt')
lenses=[inst.strip().split('\t') for inst in fr.readlines()]
lensesLabels=['age','prescript','astigmatic','tearRate']
lensesTree=createTree(lenses,lensesLabels)
treePlotter.createPlot(lensesTree)
Hi there, You’ve done an excellent job. I will certainly digg it and personally recommend to my friends. I am sure they’ll be benefited from this website.
It’s actually a nice and useful piece of info.
I’m happy that you shared this useful information with us.
Please stay us informed like this. Thank you for sharing.
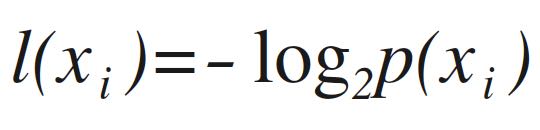
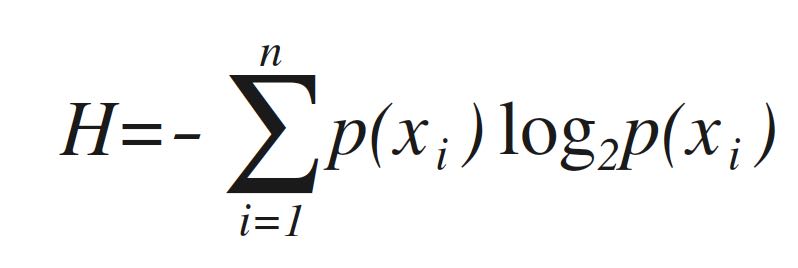

 微信扫一扫~听说打赏我的人,都进了福布斯排行榜!
微信扫一扫~听说打赏我的人,都进了福布斯排行榜!
Hi there, You’ve done an excellent job. I will certainly digg it and personally recommend to my friends. I am sure they’ll be benefited from this website.
It’s actually a nice and useful piece of info.
I’m happy that you shared this useful information with us.
Please stay us informed like this. Thank you for sharing.
Hi colleagues, its wonderful post regarding teachingand fully explained, keep it up all the time.
Thank you!I’m just a student